What is the MRCM?
The Machine Readable Concept Model (MRCM) represents rules in the SNOMED CT concept model in a form that can be read by a computer and applied to test that concept definitions and expressions comply with the rules. The MRCM may be used for a variety of purposes, including the authoring and validation of SNOMED CT concepts, expressions, expression constraints and queries, Natural Language Processing and terminology binding to support semantic interoperability.
Why is the MRCM needed?
The MRCM may be useful in a number of use cases, including:
- Development of precoordinated terminology content.
- Authoring and validation of SNOMED CT expressions, constraints and queries.
- Natural Language Processing.
- Terminology binding to information models, for purposes such as data capture and semantic interoperability.
How is the MRCM structured?
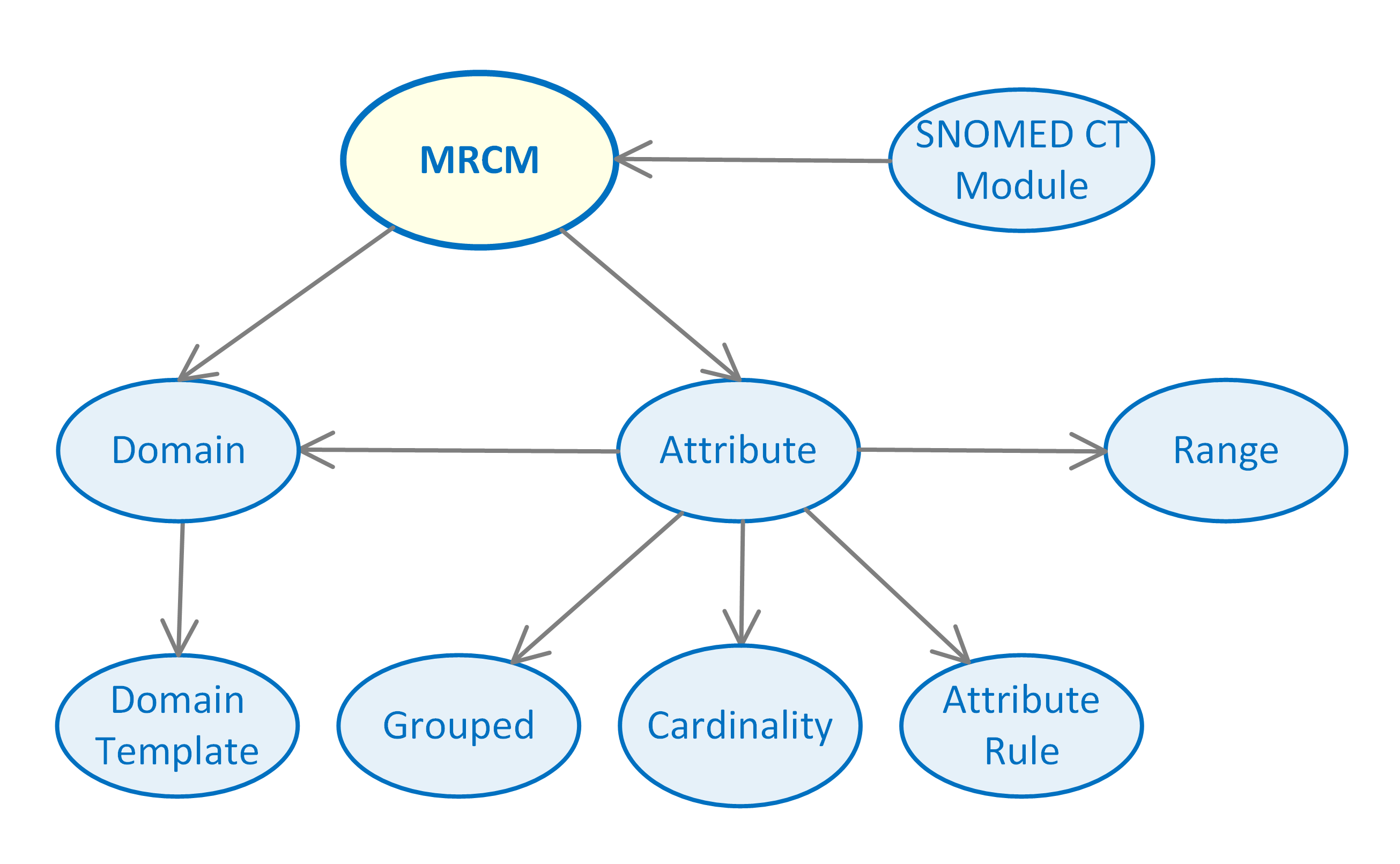
The MRCM contains a set of domains and a set of attributes, which may be applied to one or more domains. The cardinality and valid range of each attribute is specified, and indicates whether or not the attribute should be grouped. The domain, range, cardinality and grouped indicator for each attribute is also combined into a single 'attribute rule', which is represented using a SNOMED CT Expression Constraint.
For each domain, the set of valid attributes and their associated rules are compiled into two SNOMED CT 'domain templates' – for precoordinated concept authoring and postcoordinated expression authoring respectively. These domain templates may be further specialized to support customized authoring of specific subdomains.
The following diagram summarizes the logical structure of the MRCM:
How is the MRCM distributed?
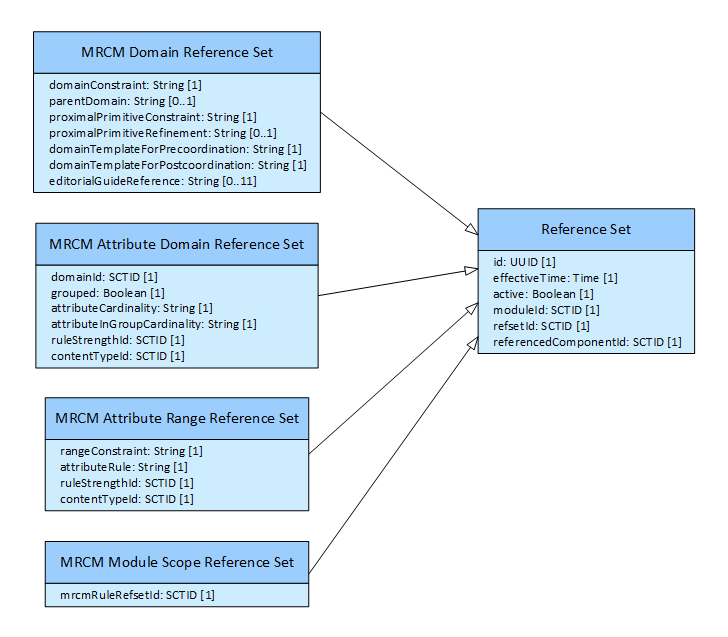
The MRCM is distributed as the following types of reference set in the SNOMED CT RF2 release file format:
- MRCM Domain Reference Set
- MRCM Attribute Domain Reference Set
- MRCM Attribute Range Reference Set
- MRCM Module Scope Reference Set
The following diagram summarizes these reference sets and their properties:
Related How To... Guides
Further Reading
SNOMED CT Glossary: Expression Constraint