Welcome and agenda | |
|
| Concrete Values | Linda Bird | Languages - New Versions to be published: SCG, ECL, STS, ETL with Boolean datatype.
MRCM - Questions
- Should numeric ranges be represented in the MRCM attribute range refset as:
- int (>0..) , int (0..)
- dec (>0..)
- or as
- int (>#0..) , int (#0..)
- dec (>0..)
- Notes
Diagramming Guideline - Suggestion - grey for concrete
 - Should the '#' and '"' appear in the diagram symbol?
- Should there be a different symbol to represent any concrete value? (since colour is optional)
  (graphviz shape) - nothing suitable available in svg or D3 (graphviz shape) - nothing suitable available in svg or D3
|
| Expression Constraint Language | Linda Bird | Recent Updates to WIP 5.2-NEW Long Syntax (Informative) - Updated to allow the full word to (optionally) be used for "synonym", "fullyspecifiedname", "definition", "acceptable" and "preferred" - 5.5-NEW Collation of Term Filters - Draft wording added for review and editing
This Week's Questions - Confirm wording re collation recommendations.
- Should we support an option to allow case sensitive searches? If so, should this be supported by (a) an additional parameter, (b) regex searching?
- Should the "caseSignificanceId" value of each description be taken into account when searching? That is, |Case insensitive|, |Case sensitive|, |Only initial character case insensitive|
On Hold - To Do - Child or self (<<!) and Parent or self (>>!)
- TERM SEARCH FILTERS - Syntax currently being drafted
- Examples
- < 404684003 |Clinical finding (finding)| {{ term = "heart att"}}
- < 404684003 |Clinical finding (finding)| {{ term != "heart att"}} – A concept for which there exists a description that does not match – E.g. Find all the descendants of |Fracture| that have a description that doesn't contain the word |Fracture|
- < 404684003 |Clinical finding (finding)| MINUS * {{ term = "heart att"}} – A concept which does not have any descriptions matching the term
- < 404684003 |Clinical finding (finding)| {{ term = match: "heart att" }} – match is word (separated by white space) prefix any order; Words in substrate are ....; Search term delimiters are any mws
- < 404684003 |Clinical finding (finding)| {{ term = wild: "heart* *ack" }}
- < 404684003 |Clinical finding (finding)| {{ term = ("heart" "att") }}
- < 404684003 |Clinical finding (finding)| {{ term != ("heart" "att") }} – matches concepts with a description that doesn't match "heart" or "att"
- < 404684003 |Clinical finding (finding)| {{ TERM = (MATCH:"heart" WILD:"*ack") }}
- < 404684003 |Clinical finding (finding)| {{ term = "myo", term = wild:"*ack" }} — Exists one term that matches both "myo" and "*ack"
- < 404684003 |Clinical finding (finding)| {{ term = "myo" }} {{ term = wild:"*ack" }} -– Exists one term that matches "myo", and exists a term that matches "*ack" (filters may match on either same term, or different terms)
- < 404684003 |Clinical finding (finding)| {{ term = "hjärta", language = se }}
- < 404684003 |Clinical finding (finding)| {{ term = "hjärta", language = SE, typeId = 900000000000013009 |synonym| }}
- < 404684003 |Clinical finding (finding)| {{ term = "hjärta", language = SE, typeId = (900000000000013009 |synonym| 900000000000003001 |fully specified name|)}}
- < 404684003 |Clinical finding (finding)| {{ term = "hjärta", language = SE, typeId != 900000000000550004 |Definition|}}
- < 404684003 |Clinical finding (finding)| {{ term = "hjärta", language = SE, type = syn }}
- < 404684003 |Clinical finding (finding)| {{ term = "hjärta", language = SE, type != def }}
- < 404684003 |Clinical finding (finding)| {{ term = "hjärta", language = SE, type = (syn fsn) }}
- < 404684003 |Clinical finding (finding)| {{ term = "hjärta", language = SE, type != (syn fsn) }}
- < 404684003 |Clinical finding (finding)| {{ term = "cardio", dialectId = 900000000000508004 |GB English| }}
- < 404684003 |Clinical finding (finding)| {{ term = "card", dialectId = ( 999001261000000100 |National Health Service realm language reference set (clinical part)|
999000691000001104 |National Health Service realm language reference set (pharmacy part)| ) }}
- < 404684003 |Clinical finding (finding)| {{ term = "card", dialect = en-gb }}
- < 404684003 |Clinical finding (finding)| {{ dialect != en-gb }}
- < 404684003 |Clinical finding (finding)| {{ term = "card", dialect = ( en-nhs-clinical en-nhs-pharmacy ) }}
- < 404684003 |Clinical finding (finding)| {{ term = "card", dialect = en-nhs-clinical (900000000000548007 |Preferred|) }}
- < 404684003 |Clinical finding (finding)| {{ term = "card", dialect = en-nhs-clinical (prefer) }}
- < 404684003 |Clinical finding (finding)| {{ term = "card", dialect = en-nhs-clinical (accept) }}
- < 404684003 |Clinical finding (finding)| {{ term = "card", dialect = en-nhs-clinical (prefer accept), dialect = en-gb (prefer) }}
- < 404684003 |Clinical finding| MINUS * {{ dialect = en-nhs-clinical}}
- < 73211009 |diabetes| MINUS * {{ dialect = en-nz-patient }}
- < 73211009 |diabetes| MINUS < 73211009 |diabetes| {{ dialect = en-nz-patient }}
- < 73211009 |diabetes| {{ term = "type" }} MINUS < 73211009 |diabetes| {{ dialect = en-nz-patient }}
- (< 404684003 |Clinical finding|:363698007|Finding site| = 80891009 |Heart structure|) {{ term = "card" }} MINUS < (404684003 |Clinical finding|:363698007|Finding site| = 80891009 |Heart structure|) {{ dialect = en-nz-patient }}
- < 73211009 |Diabetes| {{ term = "type" }} OR < 49601007 |Disorder of cardiovascular system (disorder)| {{ dialect = en-nz-patient }}
- Previous Decisions
- Wild Term Filter - Everything inside the quotation marks is the search term (including leading and trailing spaces - Note: Match term is tokenized, but wild search is not
- Acceptability will be an option directly attached to a dialect filter - for example:
- * {{ term = "card", dialect = en-nhs-clinical (accept prefer), dialect = en-gb (prefer) }}
- * {{ term = "card", dialect = en-nhs-clinical, dialect != en-nhs-clinical (accept), dialect = en-gb (900000000000548007 |Preferred| ) }}
The default behaviour of a system implementing these ECL queries with term searching, is to use asymmetric searching at the secondary level. This means that the search is, by default, case insensitive, with some character normalization behaviour (as determined by the value of the language). Which characters are normalized in the search string and target term index should be determined using the CLDR (Collation Locale Data Repository) rules for the given language. "This means that characters in the search that are unmarked will match a character in the target that is either marked or unmarked at the same level, but a character in the query that is marked will only match a character in the target that is marked in the same way. At the secondary level, an unaccented 'e' would be treated as unmarked, while the accented letters ‘é’, ‘è’ would (in English) be treated as marked. Thus a lowercase query character matches that character or the uppercase version of that character, and an unaccented query character matches that character or any accented version of that character even if strength is set to secondary." [http://www.unicode.org/reports/tr10/#Asymmetric_Search_Secondary]
- DONE - Send recommendation to MAG to consider the following
- Dialect Alias Refset
- Alternative 1 - Annotation Refset
- Dialect_Alias refset : alias + languageRefset-conceptId - e.g. "en-GB", 900000000000508004
- Example row
- referencedComponentId = 999001261000000100
- dialectAlias = nhs-clinical
- Alternative 2 - Add alias as a synonym to the language refset concept
- Create a simple type refset that refers to the preferred alias for each language refset
2. Constructing a Language Refset from other Language Refset
- Allowing an intensional definition for a language refset
- Includes order/precedence of language refsets being combined
- Potential Use cases - Note some of these will be out of scope for the simple ECL filters
- Find concepts with a term which matches "car" that is preferred in one language refset and not acceptable in another
- Find the concepts that ..... have a PT = X in language refset = Y
- Find the concepts that ..... have a Syn = X in language refset = Y
- Find the concepts that ... have one matching description in one language, and another matching description in another language
- Find the concepts that have a matching description that is in language refset X and not in language refset Y
- Find the concepts that .... have a matching description that is either preferred in one language refset and/or acceptable in another language refset
- Returning the set of concepts, for which there exists a description that matches the filter
- Intentionally define a reference set for chronic disease. Starting point was ECL with modelling; This misses concepts modelled using the pattern you would expect. So important in building out that reference set.
- Authors quality assuring names of concepts
- Checking translations, retranslating. Queries for a concept that has one word in Swedish, another word in English
- AU use case would have at most 3 or 4 words in match
- Consistency of implementation in different terminology services
- Authoring use cases currently supported by description templates
- A set of the "*ectomy"s and "*itis"s
|
| Querying Refset Attributes | Linda Bird | Proposed syntax to support querying and return of alternative refset attributes (To be included in the SNOMED Query Language) - Example use cases
- Execution of maps from international substance concepts to AMT substance concepts
- Find the anatomical parts of a given anatomy structure concept (in |Anatomy structure and part association reference set)
- Find potential replacement concepts for an inactive concept in record
- Find the order of a given concept in an Ordered component reference set
- Find a concept with a given order in an Ordered component reference set
- Potential syntax to consider (brainstorming ideas)
- SELECT ??
- SELECT 123 |referenced component|, 456 |target component|
FROM 799 |Anatomy structure and part association refset|
WHERE 123 |referenced component| = (< 888 |Upper abdomen structure| {{ term = "*heart*" }} ) - SELECT id, moduleId
FROM concept
WHERE id IN (< |Clinical finding|)
AND definitionStatus = |primitive| - SELECT id, moduleId
FROM concept, ECL("< |Clinical finding") CF
WHERE concept.id = CF.sctid
AND definitionStatus = |primitive| - SELECT ??? |id|, ??? |moduleId|
FROM concept ( < |Clinical finding| {{ term = "*heart*" }} {{ definitionStatus = |primitive| }} ) - Question - Can we assume some table joins - e.g. Concept.id = Description.conceptId etc ??
- Examples
- Try to recast relationships table as a Refset table → + graph-based extension
- Find primitive concepts in a hierarchy
- ROW ... ?
- ROWOF (|Anatomy structure and part association refset|) ? (|referenced component| , |target component|)
- same as: ^ |Anatomy structure and part association refset|
- ROWOF (|Anatomy structure and part association refset|) . |referenced component|
- same as: ^ |Anatomy structure and part association refset|
- ROWOF (|Anatomy structure and part association refset|) {{ |referenced component| = << |Upper abdomen structure|}} ? |targetComponentId|
- ROWOF (< 900000000000496009|Simple map type reference set| {{ term = "*My hospital*"}}) {{ 449608002|Referenced component| = 80581009 |Upper abdomen structure|}} ? 900000000000505001 |Map target|
- (ROW (< 900000000000496009|Simple map type reference set| {{ term = "*My hospital*"}}) : 449608002|Referenced component| = 80581009 |Upper abdomen structure| ).900000000000505001 |Map target|
- # ... ?
- # |Anatomy structure and part association refset| ? |referenced component\
- # (|Anatomy struture and part association refset| {{|referenced component| = << |Upper abdomen structure|) ? |targetComponentid|
- ? notation + Filter refinement
- |Anatomy structure and part association refset| ? |targetComponentId|
- |Anatomy structure and part association refset| ? |referencedComponent| (Same as ^ |Anatomy structure and part association refset|)
(|Anatomy structure and part association refset| {{ |referencedComponent| = << |Upper abdomen structure}} )? |targetComponentId| - ( |Anatomy structure and part association refset| {{ |targetComponentId| = << |Upper abdomen structure}} ) ? |referencedComponent|
- ( |My ordered component refset|: |Referenced component| = |Upper abdomen structure ) ? |priority order|
- ? |My ordered component refset| {{ |Referenced component| = |Upper abdomen structure| }} . |priority order|
- ? |My ordered component refset| . |referenced component|
- equivalent to ^ |My ordered component refset|
- ? (<|My ordered component refset|) {{ |Referenced component| = |Upper abdomen structure| }} . |priority order|
- ? (<|My ordered component refset| {{ term = "*map"}} ) {{ |Referenced component| = |Upper abdomen structure| }} . |priority order|
- REFSETROWS (<|My ordered component refset| {{ term = "*map"}} ) {{ |Referenced component| = |Upper abdomen structure| }} SELECT |priority order|
- Specify value to be returned
- ? 449608002 |Referenced component|?
734139008 |Anatomy structure and part association refset|
- ^ 734139008 |Anatomy structure and part association refset| (Same as previous)
- ? 900000000000533001 |Association target component|?
734139008 |Anatomy structure and part association refset| - ? 900000000000533001 |Association target component|?
734139008 |Anatomy structure and part association refset| :
449608002 |ReferencedComponent| = << |Upper abdomen structure| - ? 900000000000533001 |Association target component|?
734139008 |Anatomy structure and part association refset|
{{ 449608002 |referencedComponent| = << |Upper abdomen structure| }} - (? 900000000000533001 |Association target component|?
734139008 |Anatomy structure and part association refset| :
449608002 |ReferencedComponent| = (<< |Upper abdomen structure|) : |Finding site| = *)
|
| Returning Attributes | Michael Lawley | Proposal (by Michael) for discussion - Currently ECL expressions can match (return) concepts that are either the source or the target of a relationship triple (target is accessed via the 'reverse' notation or 'dot notation', but not the relationship type (ie attribute name) itself.
For example, I can write: << 404684003|Clinical finding| : 363698007|Finding site| = <<66019005|Limb structure| << 404684003|Clinical finding| . 363698007|Finding site| But I can't get all the attribute names that are used by << 404684003|Clinical finding| - Perhaps something like:
- ? R.type ? (<< 404684003 |Clinical finding|)
- This could be extended to, for example, return different values - e.g.
- ? |Simple map refset|.|maptarget| ? (^|Simple map refset| AND < |Fracture|)
|
| Reverse Member Of | Michael Lawley | Proposal for discussion What refsets is a given concept (e.g. 421235005 |Structure of femur|) a member of? - Possible new notation for this:
- ^ . 421235005 |Structure of femur|
- ? X ? 421235005 |Structure of femur| = ^ X
|
Expression Templates | | - ON HOLD WAITING FROM IMPLEMENTATION FEEDBACK FROM INTERNAL TECH TEAM
- WIP version - https://confluence.ihtsdotools.org/display/WIPSTS/Template+Syntax+Specification
- Added a 'default' constraint to each replacement slot - e.g. default (72673000 |Bone structure (body structure)|)
- Enabling 'slot references' to be used within the value constraint of a replacement slot - e.g. [[ +id (<< 123037004 |Body structure| MINUS << $findingSite2) @findingSite1]]
- Allowing repeating role groups to be referenced using an array - e.g. $rolegroup[1] or $rolegroup[!=SELF]
- Allow reference to 'SELF' in role group arrays
- Adding 'sameValue' and 'allOrNone' constraints to information slots - e.g. sameValue ($site), allOrNone ($occurrence)
- See changes in red here: 5.1. Normative Specification
Examples: [[+id]]: [[1..*] @my_group sameValue(morphology)] { |Finding site| = [[ +id (<<123037004 |Body structure (body structure)| MINUS << $site[! SELF ] ) @site ]] , |Associated morphology| = [[ +id @my_morphology ]] } - Implementation feedback on draft updates to Expression Template Language syntax
- Use cases from the Quality Improvement Project:
- Multiple instances of the same role group, with some attributes the same and others different. Eg same morphology, potentially different finding sites.
Note that QI Project is coming from a radically different use case. Instead of filling template slots, we're looking at existing content and asking "exactly how does this concept fail to comply to this template?" For discussion:
[[0..1]] { [[0..1]]
246075003 |Causative agent|
= [[+id (<
410607006 |Organism|
) @Organism]] }
Is it correct to say either one of the cardinality blocks is redundant? What are the implications of 1..1 on either side? This is less obvious for the self grouped case. Road Forward for SI- Generate the parser from the ABNF and implement in the Template Service
- User Interface to a) allow users to specify template at runtime b) tabular (auto-completion) lookup → STL
- Template Service to allow multiple templates to be specified for alignment check (aligns to none-off)
- Output must clearly indicate exactly what feature of concept caused misalignment, and what condition was not met.
Additional note: QI project is no longer working in subhierarchies. Every 'set' of concepts is selected via ECL. In fact most reports should now move to this way of working since a subhierarchy is the trivial case. For a given template, we additionally specify the "domain" to which it should be applied via ECL. This is much more specific than using the focus concept which is usually the PPP eg Disease. FYI Michael Chu |
| Description Templates | Kai Kewley | - Previous discussion (in Malaysia)
- Overview of current use
- Review of General rules for generating descriptions
- Removing tags, words
- Conditional removal of words
- Automatic case significance
- Generating PTs from target PTs
- Reordering terms
- Mechanism for sharing general rules - inheritance? include?
- Description Templates for translation
- Status of planned specification
|
Query Language
- Summary from previous meetings
| | FUTURE WORK Examples: version and dialect Notes
- Allow nested where, version, language
- Scope of variables is inner query
|
| Confirm next meeting date/time | | Next meeting is scheduled for Wednesday 22nd April 2020 at 20:00 UTC. |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4 Comments
Ed Cheetham
Dear all
Following up on the discussion about diagramming convention for concrete domains...
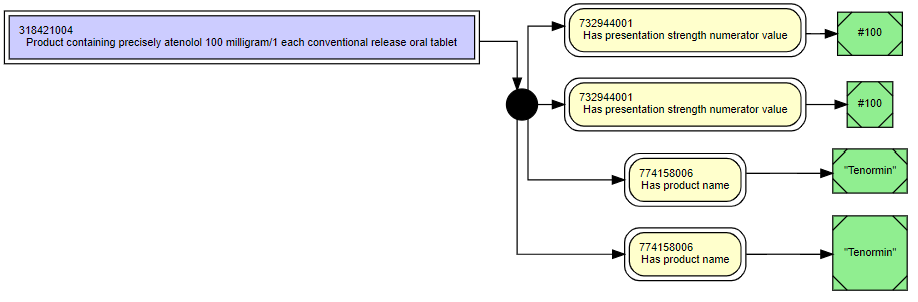
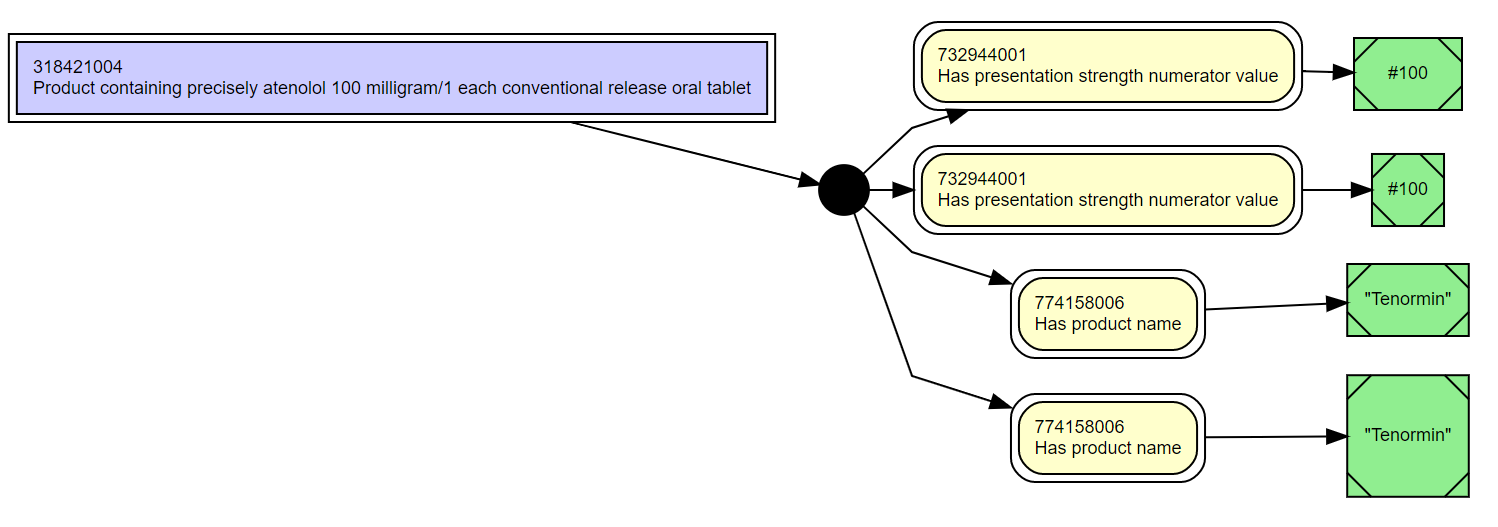
It looks as though graphviz's Msquare shape has fixed proportions, so will grow as tall as it is wide when long captions/labels are used which is not ideal. Happily however, specifying a simple box/rectangle to have a style of 'diagonals' creates the required 'line at each corner' effect but with a box that behaves as intended (just growing in length). The following diagram snippet shows both in use:
digraph { rankdir=LR; ranksep=.3; splines=ortho; node [shape=box, fontsize=9, fontname=Helvetica, style=filled, fillcolor=white];
/* hidden relationships */
"318421004" -> "138875005" [style=invis];
"260299005" -> "138875005" [style=invis];
"260299005_2" -> "138875005" [style=invis];
"774167006" -> "138875005" [style=invis];
"774167006_2" -> "138875005" [style=invis];
/* visible relationships */
"318421004" -> "C1" [arrowhead=normal];
"C1" -> "732944001" [arrowhead=normal];
"732944001" -> "260299005" [arrowhead=normal];
"C1" -> "732944001_2" [arrowhead=normal];
"732944001_2" -> "260299005_2" [arrowhead=normal];
"C1" -> "774158006" [arrowhead=normal];
"774158006" -> "774167006" [arrowhead=normal];
"C1" -> "774158006_2" [arrowhead=normal];
"774158006_2" -> "774167006_2" [arrowhead=normal];
/* root */
"138875005" [label="138875005\lSNOMED CT Concept", style=invis];
/* attributes */
"732944001" [label="732944001\lHas presentation strength numerator value", shape=box, peripheries=2, style="rounded,filled", fillcolor="#FFFFCC"];
"732944001_2" [label="732944001\lHas presentation strength numerator value", shape=box, peripheries=2, style="rounded,filled", fillcolor="#FFFFCC"];
"774158006" [label="774158006\lHas product name", shape=box, peripheries=2, style="rounded,filled", fillcolor="#FFFFCC"];
"774158006_2" [label="774158006\lHas product name", shape=box, peripheries=2, style="rounded,filled", fillcolor="#FFFFCC"];
/* classes */
"318421004" [label="318421004\lProduct containing precisely atenolol 100 milligram/1 each conventional release oral tablet", shape=box, peripheries=2, style=filled, fillcolor="#CCCCFF"];
"260299005" [label="#100", shape=box, peripheries=1, style="diagonals,filled", fillcolor=lightgreen];
"260299005_2" [label="#100", shape=Msquare, peripheries=1, style=filled, fillcolor=lightgreen];
"774167006" [label="\"Tenormin\"", shape=box, peripheries=1, style="diagonals,filled", fillcolor=lightgreen];
"774167006_2" [label="\"Tenormin\"", shape=Msquare, peripheries=1, style=filled, fillcolor=lightgreen];
"C1" [shape=circle, fontsize=0, width=0, style=filled, fillcolor=black]; }
This specification generates the hypothetical diagram below (if you copy all the blue text above into the box at http://www.webgraphviz.com/ to get a similar layout and the opportunity to experiment/modify):
The lower of each pair of concrete domain boxes are the 'shape=Msquare' ones, the upper ones are the 'shape=box, style=diagonals' ones. In particular you can see that the Msquare' specified 'Tenormin' box is starting to look odd.
Ed
Linda Bird
Thanks Ed! It's good to know that this shape is relatively easy to produce electronically (even though not using Msquare).
I was, however, expecting you to use concrete-grey.
Peter G. Williams
Wow, that looks really powerful; a programming language in it's own right. I may be a little greedy here, but I was looking for a way to do the drop shadow to match the existing documentation eg 4.10 Colour
When I typed Ed Cheetham's code above into http://www.webgraphviz.com/ (cool tool) the line routing looked a bit different:
I don't think we actually say anything about line routing in the standard do we Linda Bird? There's just what we're "used to" eg
I wondered about waiting for our tooling to get into development and then I could knock up some diagrams there, but we don't do drop shadow there either. It does add a little something though, brings the diagrams up off the page a bit. FYI Chris Swires
I'll submit the WIP Diagram Standard changes as they are, and we can always add a little polish / conformity at some point in the future.
Ed Cheetham
Thanks. Yes - Webgraphviz has a peculiar handling of the splines=ortho instruction. That said, even in layouts where the angles render as true right angles I've not been able to merge the edges the way you have in the second example above and used more generally in the SI guideline. I've settled for parallel edges (extreme example from 18932005 |Rastelli operation in repair of transposition of great vessels (procedure)| attached. Nothing like as clean but 'good' enough for my purposes! Duplicate edges can be merged, and some merging can be emulated with tiny intermediate nodes, but given that ultimately the layout is at the mercy of the dot engine I decided it was too hard! Ed