SNOMED Documentation Search
Before a template can be processed, it is important that the input data is represented in a clear and unambiguous way. This is required to ensure that the template is processed in the expected manner, and the intended results are produced. In this section, we explain some of the considerations in representing and preparing the input data for processing.
Template input data may be represented in a variety of forms, ranging from flat tabular structures to nested serializations. Irrespective of the format, however, it is important that there is no ambiguity as to how each piece of input data should be used to create the resulting expressions. This can be particularly challenging where repetition of relationship groups or attribute name-value pairs is required.
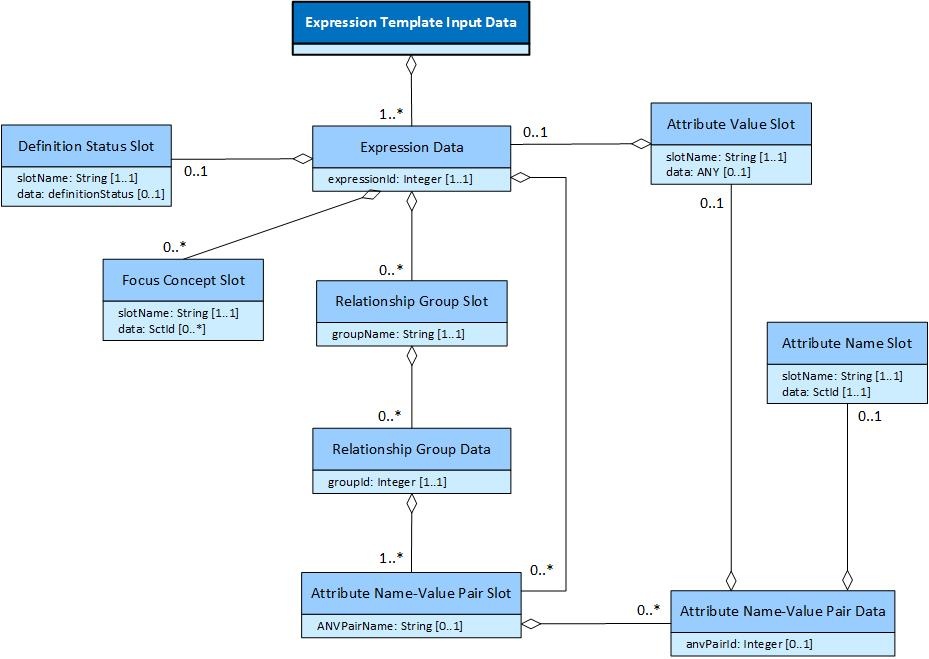
The UML diagram below illustrates the logical structure of expression template input data. Each set of Expression Template Input Data includes the data intended to be used to create one or more expressions. The data used to populate a single expression is referred to in this model as Expression Data. Each Expression Data (identified by an expression id), may include at most one Definition Status Slot (with a slot name and a definitionStatus value), zero or more Focus Concept Slots (each with a slotName and zero or more values), zero or more Relationship Group Slots (each with a group name), and zero or more ungrouped Attribute Name-Value Pair Slots (each with a name). Each Relationship Group Slot has zero or more Relationship Group Data instances in the input data (each identified by a group id). Each of these Relationship Group Data instances has input data for one to many Attribute Name-Value Pair Slots. And for each Attribute Name-Value Pair Slot within a Relationship Group Data instance, there are zero to many Attribute Name-Value Pair Data instances (identified by an anvPair id), each with at most one Attribute Name Slot (with name and value), and at most one Attribute Value Slot (with name and either a simple data value, or an Expression Data instance of its own).
In this section, we provide some examples of unambiguous expression template input data, and discuss how this input data can be used to populate each expression.
The expression template below is used to create expressions that represent a | Disease| with one or more | Finding site| and | Associated morphology| . When using expression templates, such as this one, in which attribute name-value pairs and relationship groups may be repeated, the input data should be explicit about which data values are used to populate each slot, and how these values are grouped into relationship groups.

By populating this logical model with input data, as shown below in , the expression template can be processed to generate completed expressions. Please note that the first column in the table below is used to group together the input data intended to populate each expression. Subsequent columns are named according to the associated slot in the expression template. Relationship group slots are used to group the data that is intended to populate a single relationship group. Attribute name-value slots are not required in this example. They are are only required where both the attribute name and attribute value use a slot.
Expression Data | DefStatus | Disease | Group | Site | Morphology |
|---|---|---|---|---|---|
1 | === | 1 | |||
2 | <<< | 1 | |||
2 | |||||
3 | <<< | 1 | |||
| 4 | === | 1 | |||
Using input data shown in to populate the given expression template will result in following four expressions.
The expression template below is used as a pattern for family history expressions. It contains a nested relationship group (i.e. SSgroup) inside the outer relationship group (i.e. AFgroup). To populate this expression template, the input data must be clear as to where each value should be used, and how these values should be grouped into relationship groups and expressions.
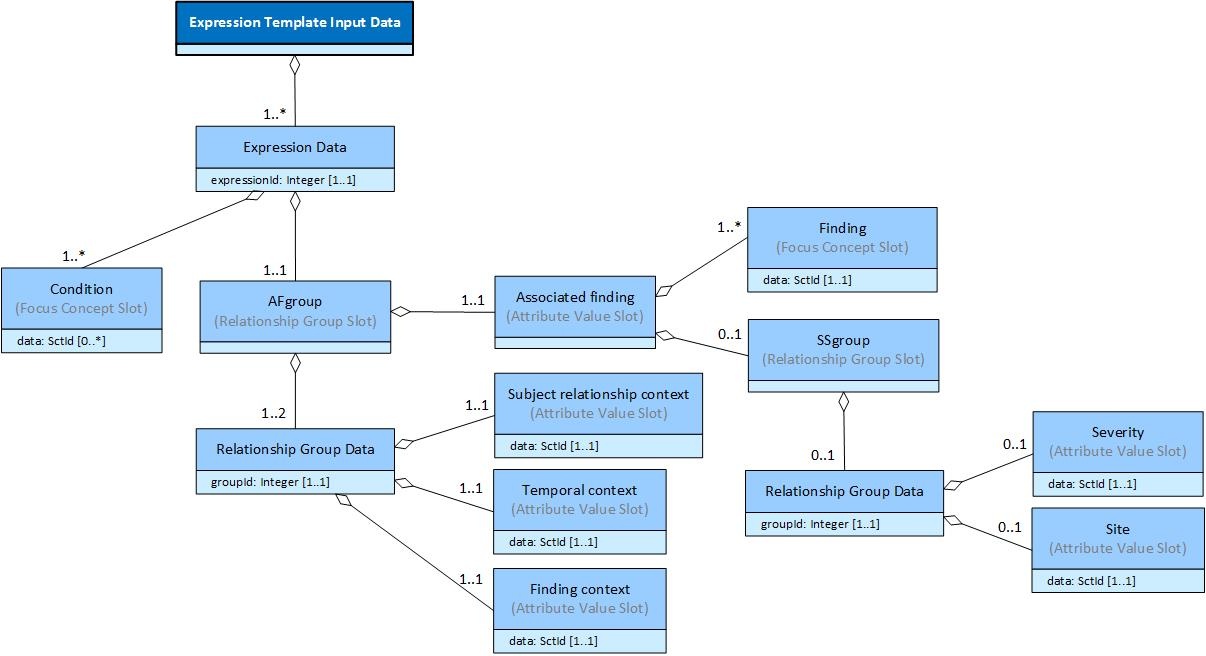
This logical model can be populated with input data, as shown below in .
| Expression Data | Condition | AFgroup | Finding | SSgroup | Severity | Site | Relationship | Time | Context |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | |||||||
| 2 | 1 | 1 | |||||||
| 2 | 1 | ||||||||
| 3 | 1 | 1 | |||||||
| 2 |
The expression template below represents a procedure with a single method and one or more procedure devices. Please note that in the first attribute name-value pair, both the attribute name and the attribute value use a slot. Because this name-value pair is repeatable, the input data needs to include an attribute name-value pair slot to ensure that the corresponding attribute name and attribute value stays connected.
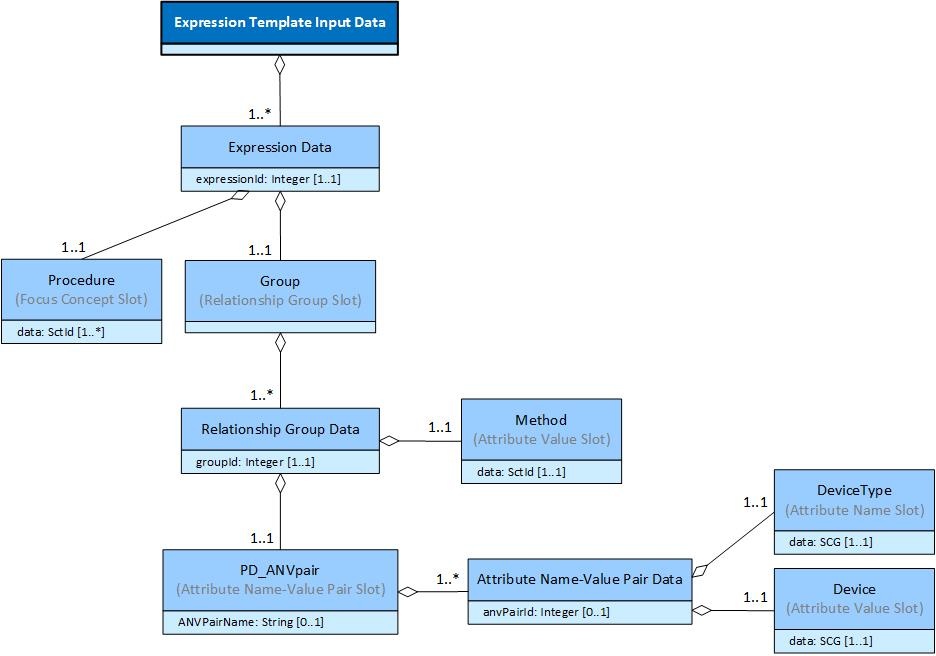
This logical model can be populated with input data, as shown below in . Please note that because the first attribute name-value pair is repeatable and uses a replacement slot for both the attribute name and attribute value, the input data needs to include the attribute name-value pair slot to ensure that the corresponding attribute name and attribute value stays connected.
Expression Data | Procedure | Group | PD_ANVpair | DeviceType | Device | Method |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | ||||
| 2 | 1 | 1 | ||||
| 2 |
| Expression | |
|---|---|
| 1 | |
| 2 | |
The expression template below represents a | Disease| with one or more values for | Finding site| and | Associated morphology| , grouped into one or more relationship groups.
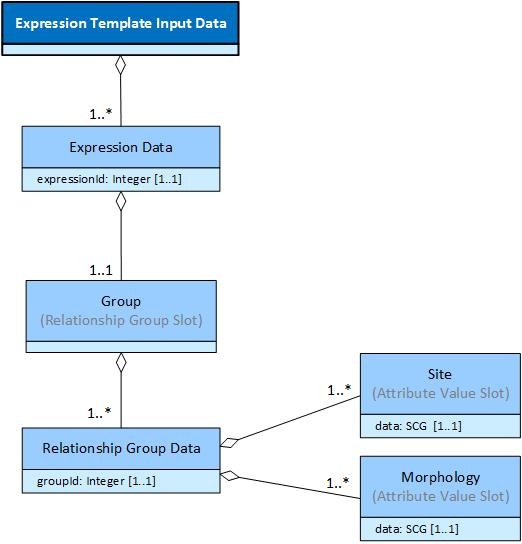
below shows some example input data for the above template represented using the tabular format used in the previous examples.
| Expression Data | Group | Site | Morphology |
| 1 | 1 | ||
2 | |||
| 2 | 1 | ||
| 3 | 1 |
In addition to this tabular representation, there are a wide variety of other possible formats for representing template input data, including json, xml, tsv, csv etc. The exact format used will depend on the format required by the template processor. For example, the above input data can be represented in JSON as shown below.
{"Expression Data": [
{ "Group": [
{ "Site":"312763008 |Bone structure of trunk|",
"Morphology":"72704001 |Fracture|" },
{ "Site": "84667006 |Bone structure of cervical vertebra|",
"Morphology": "72704001 |Fracture|" } ] },
{ "Group": [
{ "Site":"71341001 |Bone structure of femur|",
"Morphology": "72704001 |Fracture|" } ] },
{ "Group":[
{ "Site":"12611008 | Bone structure of tibia|",
"Morphology": "72704001 |Fracture|" } ] } ] }
While it is important that there is no ambiguity as to how each piece of input data should be used in processing the associated expression template, there are often opportunities to make the input data much simpler than is represented in the full logical model above. In particular:
With this in mind, the examples in 8. Expression Template Examples simplify the input data, where appropriate, using these assumptions and an implicit association with the logical model described above.